测试环境产品得很稳定,让用户相信环境是可靠的,其次环境部署需要高效,二者缺一不可。下面从这两个方面做一下阐述。


从图 1 可以看出,可靠性主要有两个:
路由隔离:需要精确。项目间调用乱窜,不仅会相互影响,还测非所测。
Stable 环境:作为基座环境必须稳定。不稳定就会影响所有依赖的项目。
通用的隔离逻辑:从项目环境发起的流量,下游默认调用项目环境,如果没有,就调用 Stable 环境兜底。这看似很简单,只要使用过都能理解,但要所有人都能理解(统一思想)又挺难。团队新人入职,都需要深入学习一遍。
因此环境组在上述通用逻辑基础上,做了账号与环境绑定的路由隔离产品:只要用户绑定了账号和环境的关系,这个账号所有到这个应用的请求,一定会走到绑定的环境上,而不用了解环境相关的任何业务逻辑。
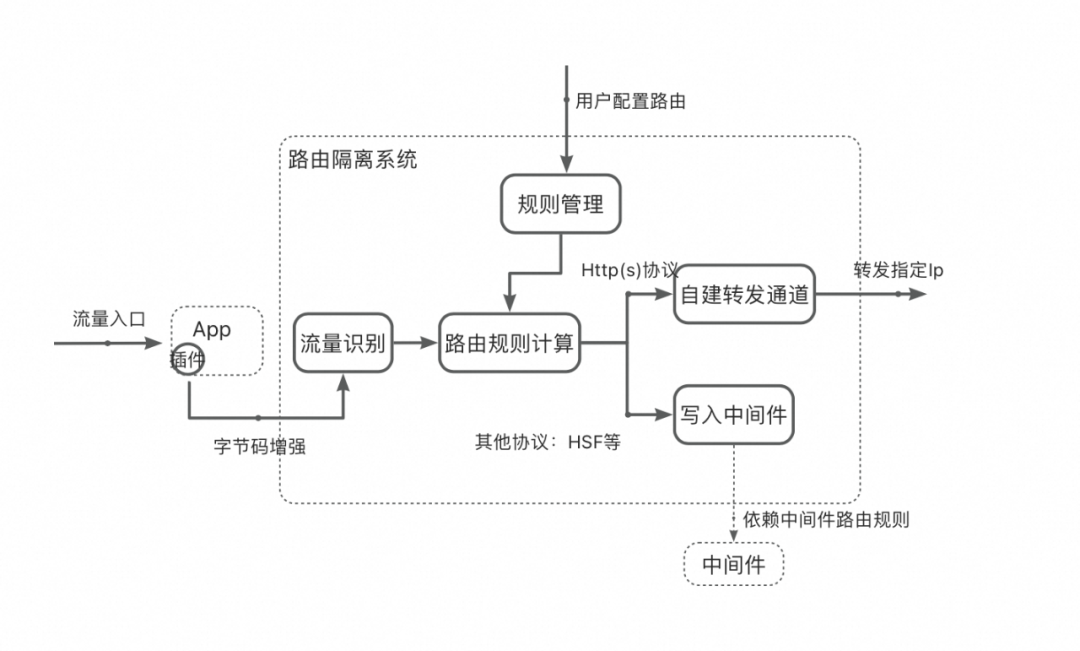
路由准确性高要求不言而喻,所以最近一年发了 120 + 迭代来提升路由系统稳定性,稳定性有了质的飞跃。总结如下:
重构字节码增强。
升级插件安装:守护进程和路由插件分离。
改进自建转发路由方案。
路由稳定性提升还在持续,长尾问题如流量账号解析等还需进一步挖掘治理。
Stable 环境作为基座环境必须稳定,因此需要对 Stable 环境进行监控。Stable 环境流量小,时有时无,和线上大流量不同,不可以通过流量下跌来判断稳定性。倘若借用线上思路,自动打大流量检测,投入产出比不高。环境组也尝试过,核心链路可行,但不具备通用性。经过这几年的实践,还是以业务视角的监控指标有用、可靠、维护成本低。
检测进程、HSF 接口心跳、磁盘空间
接口 (http (s)/HSF) 自动化巡检并断言
监控只是提前发现问题,最终还是需要解决问题,所以发现问题后,系统先进行自愈(不限于重启、磁盘清理等),后故障仍然不能消除的,报警通知责任人,走 GOC 的风险预警及故障处理流程。
监控系统还需要考虑低成本的维护,在用户不介入的前提下就有较高的监控水平。环境系统自动同步 Stable 环境的变化,在无人介入情况下,通过 fuzz 方式随机出接口测试用例并发起接口调用巡检。针对不同的环境类型,分层处理,如:fuzz 的测试用例是随机的,可以运用在线下 Stable 环境,而预发 DB 与线上共用,不能使用 fuzz 从而污染线上环境。同理,磁盘自动清理也只使用在线下。
环境的稳定,不仅仅在于服务的稳定,动态配置的一致性也至关重要。用户共用一套动态配置成本最低,而为了自己验证需要,可随意变更配置,以至于对其他用户产生影响也不自知。其他用户每次验证时不会也不可能做到 check 每个配置,就会出现 “测非所测” 情况。用户做不到的,由监控系统来兜底。
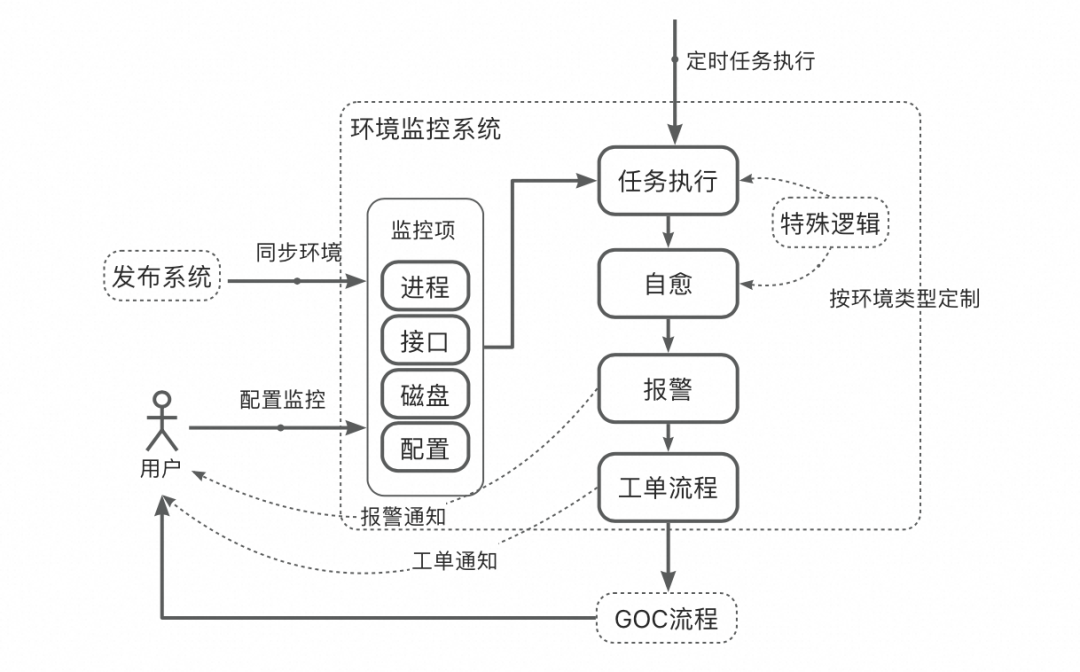
环境监控的业务监控逻辑也可以运用在线上环境,对线上环境监控是一个有力的补充。
环境报警后的问题排查就依赖可观测产品来快速排查与定位,好的可观测产品一定具备以下特点:
链路精确,不能有节点丢失
通过账号、商品、订单等业务信息能轻松获得对应的 traceId(链路 id,链路唯一标识)
沉淀参数数据,覆盖通用中间件协议与子调用
节点调用的路由正确性判断并有具体的分析
单节点应用可以查看包含 trace 的日志集合
其他特点
访问过的 trace 自动保存,任何时候都可以访问到
请求需要秒级展示
安全性:有数据脱敏能力。
在实际实施过程中,具有业务定制的技术栈如:function 函数服务等都需要关联系统对接,“逢山开路、遇水搭桥”。这也是环境治理最需要坚持的事情。
启动加速
环境可靠是基石,基石稳定后追求的自然是高效部署;一个应用构建与部署时长超过 10 分钟,感受不强烈,但是放到淘天集团的体量对效率的影响就非常巨大。以我自己应用为例,全量部署一次在 12 分钟左右,一个 feature 开发完后的第一次部署,因为心理有预期,能接受这个时长,大不了喝杯 coffee;但是改 bug 的时候,改了一行验证也是需要 12 分钟,这就很难接受了。一天通常得部署 5~6 次,但也喝不了那么多 coffee;所以,高效部署不仅仅是高效这点收益,同时是程序员的幸福感提升。
“高效部署” 这个命题,前人前赴后继做了很多的工作。去年我们环境组与阿里云 jvm 团队合作也在 cds 技术上做了研究与尝试。环境系统会自动将分支没有修改到的代码缓存起来,无需重新进行类加载,从而提升部署效率,单次部署时长缩短 30s。有一定的效果,但和总量 10 分钟相比又显的是 “萤火之光”。要想达到秒级效果,还是得死磕热部署。

图 4:热部署与部署流水线结合
代码差异检测这一点,就很难做到 100%,在当下基于 dcevm 技术、爱橙科技的 fastboot 技术基础上,再新增插件能力来解决。目前的思路是通过分层的方式:
只修改方法体的代码,直接 redefine,秒级生效
文件的增删,bean 与中间件等变更借助于 dcevm 与 fastboot 技术,做到秒级生效
对于确实无法做到的热部署的,与现有的部署方式保持不变,走全量部署。
自从尝试了一下启动加速的秒级效果,有那种 “天突然亮了” 的感觉。启动加速还在继续丰富插件来支持更多的场景,降低第三种部署方式的次数。
测试数据
测试环境高效稳定,其实还不能做到高效的验证,因为测试数据也是验证过程中的关键一环。核心团队质量 TL 明确和我说:“如果能解决好测试数据构造的问题,至少我们的效率可以再提升 30%”。可见测试数据的重要性。为此进行了相关调研,结论如下:
1. 跨部门的数据构造依旧很难
2. 自己域内容易解决,但解决方案对外部门通用性不够。
3. 链路级别的数据构造基本上需要再新起应用来包一层服务来提供,成本高。
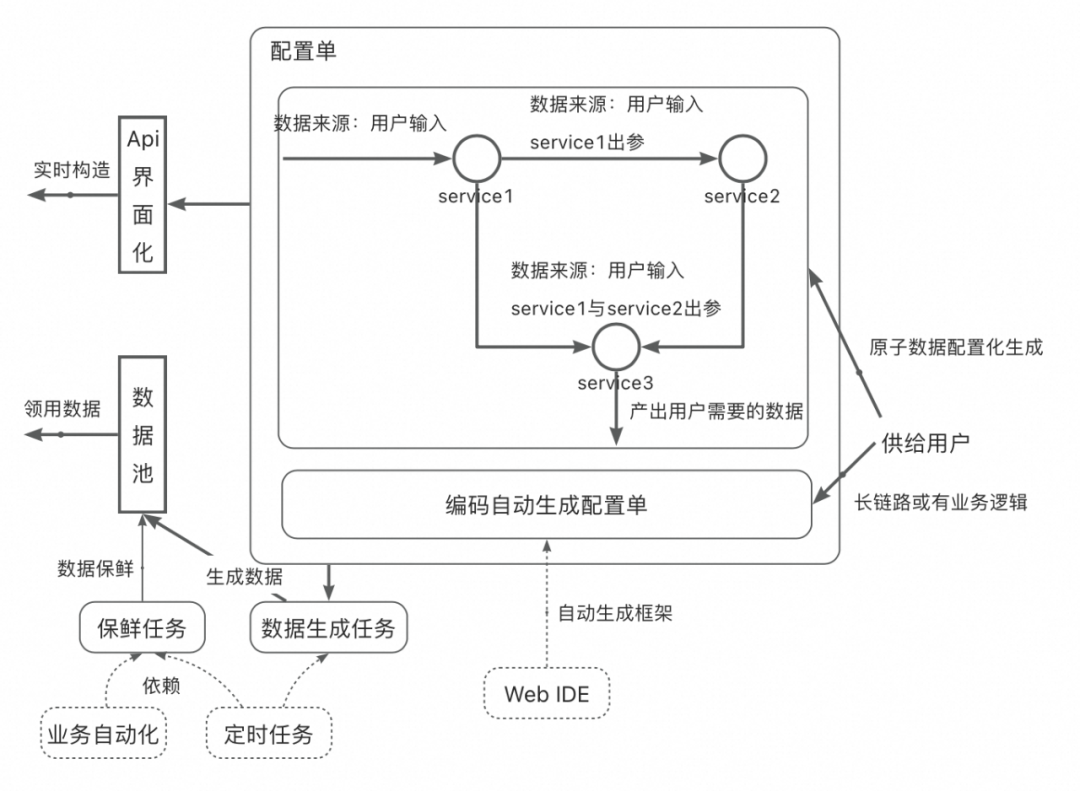
图 5:配置化数据构造示意图
配置化数据构造,提供数据构造的两大基础能力:界面化通过接口完成数据配置单配置和用户利用基础节点编码框架生成配置单。用户可以通过 Api 界面化的面包版实时构造数据,也可以通过有保鲜能力的数据池直接领用想要的数据。
开源项目推荐 helm-secrets helm-secrets是一个Helm插件,用于动态解密加密的Helm值文件。 TofuController TofuController(以前称为WeaveTF-Contr......
去年之前,阿里巴巴的淘天集团测试环境是以领域方式运作:不局限测试环境治理本身,从测试模式方法论及用好测试环境思路引领集团测试环境治理。领域运作最难的是 “统一思想......
近日,国民级办公应用WPS宣布,即将发布基于国际知名开源操作系统deepinV23的WPSOfficeForLinux个人版。该版本基于玲珑包格式,与deepinV23的智能化特色深度融合,面向......
使用KK键盘的过程中,我们可以根据自己的需要去自定义软件的头像。下面为大家介绍一下操作方法。1.打开手机中的KK键盘软件进入界面后,在右下角点击“我的”进行切换。在我的页面上方有一个“点击进入个人主页”,在它的上面点击。...
萝卜快跑,百度Apollo旗下的自动驾驶出租车服务,近期在武汉遭遇了一系列事件,引发了公众对其安全性与服务可靠性的广泛关注。接下来,小编将从四方面进行分析:萝卜快跑武汉......
凹语言项目于2019年初立项,2020年第一次开发组会议确立了"不做玩具车"的目标,2022年7月底正式开源,至今开源2周年。简单回顾在最近1年的项目进展和未来目标。凹语言主......
AI初创公司Character.AI宣布已与谷歌达成协议,向谷歌提供其当前LLM技术的非独家许可。该协议也将为Character.AI带来更多资金,以继续发展其AI产品。 与此同时,Ch......
真正的技术创新,不仅需要理论的深度,更需要实践的广度,以及极客式的探索。 2024年8月15日至16日,全球开源技术峰会GOTC2024将于上海张江科学会堂盛大开启。GOTC......
近日获悉,deepinV23Release版本将于8月15日正式上线,新版本将支持Intel最新的Ultra平台,这使得deepinV23有望成为当前市场最适合AIPC的操作系统之一。 作为一款......
在6月份因不明原因撤回诉讼后,马斯克再次对OpenAI及其首席执行官SamAltman提起了新的诉讼,声称OpenAI将利润和商业利益置于公众利益之上,还违背了免费共享或开源公司......
OpenAI联合创始人之一JohnSchulman已离开该公司,跳槽到由前OpenAI研究人员成立的的竞争对手公司Anthropic。 今年5月份,OpenAI原安全主管、超级对齐(Superalignm......
对于软件检测工程师来说,了解常规软件检测流程及基本步骤对于提高软件测试工作效率,梳理记录测试过程中发现的问题十分重要。而对于企业来说,不管是把软件测试交给第......
在信息科技行业快速发展的今天,远程控制软件逐步成为了当今社会上众多打工人的必备软件,前两年因为疫情的影响,使得大众了解到了远程软件的实用以及便利性 目前......
在忙碌的工作日中,管理日常任务和待办事项常常让人感到不胜其烦。选择合适的待办事项桌面工具,可以让你的日程变得井井有条,提升工作和生活的效率。我在这篇文章中将......
如意玲珑(Linyaps)项目已与开放原子开源基金会完成捐赠协议签署,目前如意玲珑已成为基金会的正式孵化期项目。 如意玲珑是开源软件包格式,用于替代deb、rpm等包......
为了加快向内存安全编程语言的过渡,美国国防部高级研究计划局(DARPA)正在推动程序代码转换工具TRACTOR的开发。TRACTOR是TRanslatingAllCTORust的缩写,该项目旨在开......
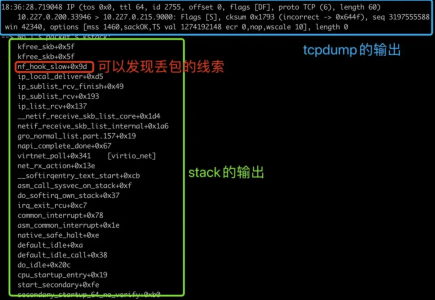
背景介绍在 Linux 内核网络开发过程中,网络丢包问题是一个常见的挑战。传统的网络抓包工具(如 tcpdump)虽然能够帮助开发者定位问题,但其效率较低,且在深度网络问题定......
近日获悉,deepinV23Release版本将于8月15日正式上线,新版本将支持Intel最新的Ultra平台,这使得deepinV23有望成为当前市场最适合AIPC的操作系统之一。 作为一款......
如意玲珑(Linyaps)项目已与开放原子开源基金会完成捐赠协议签署,目前如意玲珑已成为基金会的正式孵化期项目。 如意玲珑是开源软件包格式,用于替代deb、rpm等包......
真正的技术创新,不仅需要理论的深度,更需要实践的广度,以及极客式的探索。 2024年8月15日至16日,全球开源技术峰会GOTC2024将于上海张江科学会堂盛大开启。GOTC......
开源项目推荐 helm-secrets helm-secrets是一个Helm插件,用于动态解密加密的Helm值文件。 TofuController TofuController(以前称为WeaveTF-Contr......
近日,国民级办公应用WPS宣布,即将发布基于国际知名开源操作系统deepinV23的WPSOfficeForLinux个人版。该版本基于玲珑包格式,与deepinV23的智能化特色深度融合,面向......